Specifying a file division by using custom layouts
Custom layouts can be used to define how a file is divided into different records.
In the New Record Layout window,
specify the layout name and the namespace. In the Type list,
select Custom to configure a custom layout.
The custom layout can be used to configure individual records as values,
or as name-value pairs. For example, john|david|miller| represents
three values while first,john|middle,david|last,miller represents
three name-value pairs.
In the Fields panel, the Type field can be used to specify how each record is read or is to be written. Each type can be configured by using the options under Configuration. You can specify whether fields contain values or name-value pairs, including the name-value delimiter, under Field Content.
The following field types are available for custom layout:
- Split: The Split option can packetize (split) the contents of files, based on a
user-defined delimiter.
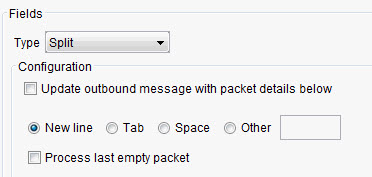
You can select one of the available delimiter types (new line, tab, space), or select Other and enter a custom delimiter character in the field provided.
When you are reading records, if the record ends with a delimiter, and you must process one more packets as an empty string "", enable the Process last empty packet option. Disable this option if the delimiter indicates that there are no more packets.
- Length: The Length option can
be used to iterate over the contents of a file to extract multiple
records.
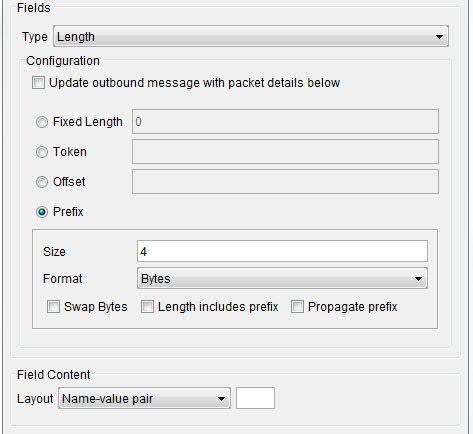
Fixed Length Each record is the same designated size. Token The string of characters that marks the start of each record. Offset Each record starts after the entered number of bytes. In the example, 16 bytes of data precede the length information. Prefix A number of bytes / characters at the start of the record that denote the length of the record. When you are using the Token, Offset, or Prefix modes, the following options control how the actual packet length is read from the stream of information.
Size The number of bytes or characters that contain the length information. Format Indicates whether the prefix values are to be treated as raw values (Bytes) or translated from their ASCII equivalent (ASCII). Swap Bytes Indicates whether the transport swaps the order of the bytes before it treats the data as the length of the record. Length includes prefix Indicates whether the length includes the prefix (information about the length of the message). Propagate prefix Indicates whether the prefix portion of the message is propagated to subscribers. - Delimited: The Delimited option can be used to
iterate over the contents of a file and extract multiple records that
are designated by a start and end token.
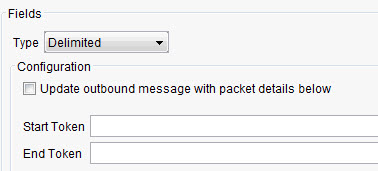
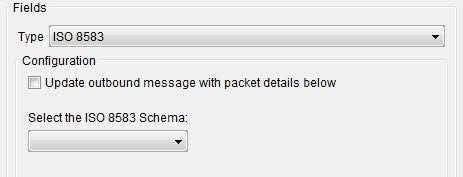
Start Token A series of characters that denotes the start of a record. End Token A series of characters that denotes the end of a record. - ISO 8583: Select from the list of ISO 8583 schemas
to allow the application of the selected schema to text messages and
binary messages.
- Swift: The Swift option can be used to break up the contents of the file into a SWIFT message that is based on simple SWIFT rules (that is, {n:...}).
 Note: At any time, Rational® Integration Tester supports only one version of SWIFT. Rational® Integration Tester is updated annually to support the next version of SWIFT.
Note: At any time, Rational® Integration Tester supports only one version of SWIFT. Rational® Integration Tester is updated annually to support the next version of SWIFT. - Token: The Token option is similar to the Delimited
option, but can be used when you need to specify more data after the
end token.
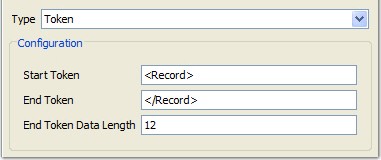
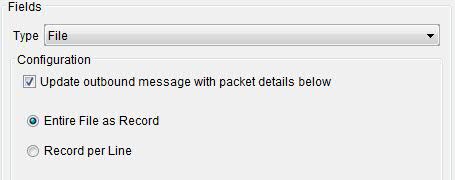
Start Token A series of characters that denotes the start of a record. End Token A series of characters that denotes the end of a record. End Token Data Length An optional quantity of data that can be present following the end token. - File: When you use a file as a single record,
the record definition can use the entire file as a single record,
or treat each line as a record.